概要
今回紹介するnotebookは[For Beginners] Tackling Toxic Using Kerasです。このnotebookではKerasのLSTMを用いたテキスト分類について書かれています。特に初学者向けに書かれているnotebookであり、KerasやLSTMについて、そしてそれをテキスト分類に応用する方法が詳細に記されています。それではnotebookの内容を見ていきましょう!
内容
目次
- データの前処理
- モデルの構築
- モデルの学習
データの前処理
import sys, os, re, csv, codecs, numpy as np, pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.layers import Dense, Input, LSTM, Embedding, Dropout, Activation
from keras.layers import Bidirectional, GlobalMaxPool1D
from keras.models import Model
from keras import initializers, regularizers, constraints, optimizers, layers
データをロード。参考のnotebookから取得。
train = pd.read_csv('../input/train.csv')
test = pd.read_csv('../input/test.csv')
データの確認
train.head()
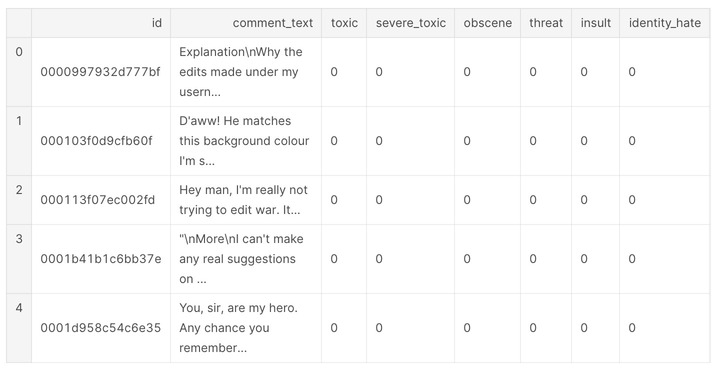
まずはじめに欠損値の確認。欠損値がある場合、モデリングする段階でつまづいてしまいます。今回の場合は欠損値がないため、欠損値に対する処理はする必要がなさそうです。
train.isnull().any(),test.isnull().any()

続いてトレーニングデータをX(説明変数)とY(目的変数)に分割します。
list_classes = ["toxic", "severe_toxic", "obscene", "threat", "insult", "identity_hate"]
y = train[list_classes].values
list_sentences_train = train["comment_text"]
list_sentences_test = test["comment_text"]
LSTMのネットワークにデータを入力するためには単語のデータを数値に変換する必要があります。データを変換するために今回行う処理は以下の通りです。
- Tokenization - 文章をユニークな単語に分解。例えば"I love cats and love dogs"を
["I", "love", "cats", "and", "dogs"]のように分解します。 - Indexing - 先ほどのユニークな単語を辞書型の構造にして、インデックスを付けていきます。例えば、
{1:"I"、 2:"love"、 3:"cats"、 4:"and"、 5:"dogs"}のような形です。 - Index Representation - 文章内の単語をインデックスの形式に表現し文章を数値化します。これでLSTMの入力データとなります。例えば、“I love cats and love dogs"が
[1, 2, 3, 4, 2, 5]になります。
上記の処理は、Kerasを用いるとすごく簡単にできます。文章をトークン化するときに、辞書内のユニークな単語の数を定義する必要があることに注意してください。
max_features = 20000
tokenizer = Tokenizer(num_words=max_features)
tokenizer.fit_on_texts(list(list_sentences_train))
list_tokenized_train = tokenizer.texts_to_sequences(list_sentences_train)
list_tokenized_test = tokenizer.texts_to_sequences(list_sentences_test)
辞書を用いて各単語の出現回数とインデックスを調べることもできます。
#commented it due to long output
#for occurence of words
#tokenizer.word_counts
#for index of words
#tokenizer.word_index
ここで、list_tokenized_trainを見ると、単語をインデックス表現に変換できていることがわかります。
list_tokenized_train[:1]

(略)
しかしこのままでは問題があります。それは文章の長さがそれぞれで異なるからです。例えば”I love cats and love dogs”と”I love cats”の場合インデックス表現した文章は次のようになります。
- ”I love cats and love dogs” → [1,2,3,4,2,5]
- ”I love cats” → [1,2,3]
このように特徴量の数が異なってしまい、このままでは入力データとしては使えません。なので特徴量の数を揃える必要があります。
これを解決するためにPaddingという処理を行います。これは短い文章に対しては、不足分をゼロで埋めることで同じ長さにします。また長い文章に対してはトリミングを行い、同じ長さに変形します。 今回は最大長を200に設定しています。
maxlen = 200
X_t = pad_sequences(list_tokenized_train, maxlen=maxlen)
X_te = pad_sequences(list_tokenized_test, maxlen=maxlen)
ちなみにどのように最適なmaxlenを設定するか知っていますか? 短すぎると有用な情報が失われる可能性があり、精度が低下する可能性があります。一方で長すぎるとLSTMのセルを大きくしすぎてしまいます。
1つの方法として、文章の長さの分布をみる方法があります。
totalNumWords = [len(one_comment) for one_comment in list_tokenized_train]
plt.hist(totalNumWords,bins = np.arange(0,410,10))
plt.show()
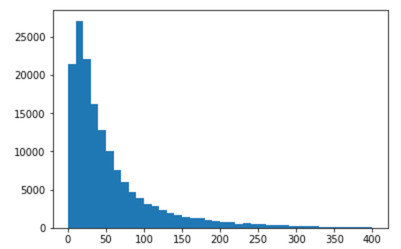
ご覧のとおり、文の長さのほとんどは約30以上です。 maxlenを50に設定することもできましたが、私(notebook著者が)は偏執狂なので200に設定しました。このように実験をして、マジックナンバーを確認することができます。
モデルの構築
以下の図が、構築しようとしているモデルのアーキテクチャです。
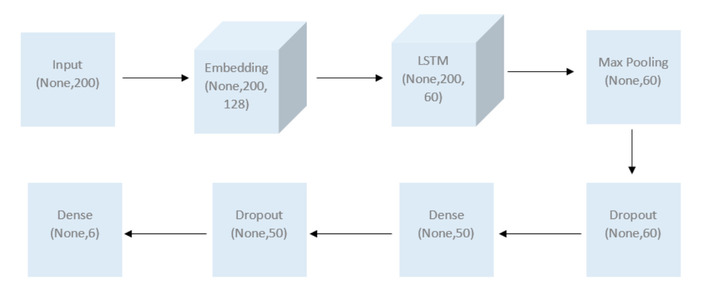
はじめに上記で処理をしたデータをネットワークの入力とします。なので200次元のデータを受け入れる入力レイヤーの定義をします。
inp = Input(shape=(maxlen, )) #maxlen=200 as defined earlier
次に、それをEmbeddingレイヤーに渡し、文章内の単語を定義されたベクトル空間に変換していきます。単純にone-hot encodingを使用した場合に特徴量が膨大になってしまうのに対して。Embeddingを利用するとモデルのサイズを削減できます。 Embeddingレイヤーの出力は、ベクトル空間内の単語の座標のリストになります。 たとえば (-81.012)は「cat」、(-80.012)は「dog」となります。 これらの座標の距離を利用して、関連性とコンテキストを検出することもできます。Embeddingは非常に面白い分野なので興味がある方は以下のリンクを参考にしてください。 Embedding参考リンク : https://www.analyticsvidhya.com/blog/2017/06/word-embeddings-count-word2veec/
上記の「ベクトル空間」のサイズと、使用している一意の単語(max_features)の数を定義する必要があります。モデル精度を良くするにはここのパラメータチューニングを考えた方がいいです。
embed_size = 128
x = Embedding(max_features, embed_size)(inp)
Embeddingレイヤーは、(None、200、128)の3次元テンソルを出力します。 これは文章の配列であり、各単語(200)に対して、Embeddingのベクトル空間に128座標の配列があります。
次に、このTensorをLSTMレイヤーにフィードします。次元が60の出力を生成するようにLSTMを設定し、展開された結果のシーケンス全体を返すようにします。LSTMまたはRNNは時系列ニューラルネットワークであり、前のネットワークの出力を次のネットワークの入力に再帰的にフィードしていきます。
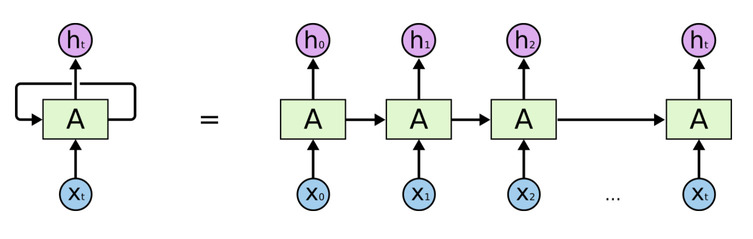
x = LSTM(60, return_sequences=True,name='lstm_layer')(x)
出力を通常のレイヤーに渡す前に、3Dテンソルを2Dテンソルに変換する必要があります。 ここでは、CNNで伝統的に使用されているGlobal Max Poolingレイヤーを使用します。 簡単に言うと、データの各パッチを調べ、各パッチの最大値をとり、新しいデータセットとしてます。プーリングレイヤーにはさまざまなバリアント(Average、Maxなど)が次元削減に使用されており、異なる結果が得られる可能性があるため、実際にいろいろ実験してみてください。
x = GlobalMaxPool1D()(x)
次にDropoutレイヤーをいれていきます。この処理を入れることでランダムにノードが無効化され、モデルの性能がよくなることが一般的に知られています。今回は0.1(10%)に設定しておきます。
x = Dropout(0.1)(x)
Dropoutレイヤーの後、全結合層+relu関数を利用します。今回はユニット数を50にしています。
x = Dense(50, activation="relu")(x)
そして再びDropoutレイヤー。
x = Dropout(0.1)(x)
そして最後の層にsigmoidを追加します。これはそれぞれのラベル(ここでは6このラベル)に対して、0,1のバイナリ分類をするためです。
x = Dense(6, activation="sigmoid")(x)
あとは、入力、出力を定義し、学習プロセスを構成するだけです。 ここでは最適化にAdam、、損失関数を0, 1分類のためbinary_crossentropyに定義します。
model = Model(inputs=inp, outputs=x)
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
モデルの学習
batch_size = 32
epochs = 2
model.fit(X_t ,y, batch_size=batch_size, epochs=epochs, validation_split=0.1)
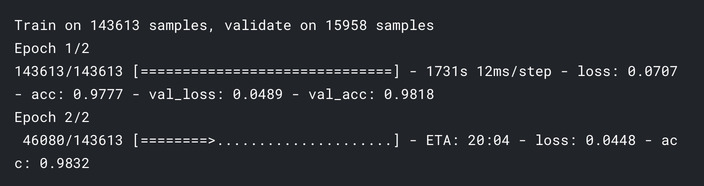
基本的な実験にしてはかなりよい精度なことがわかるかと思います!
最後に
今回はLSTMを用いたテキスト分類について書かれたnotebookについて見ていきました。本文にはより詳細に書かれている部分もあるので余力のある方は是非ごらんください。