はじめに
ここではハミング距離とはなにかの説明と、pythonでの計算方法を紹介します。
ハミング距離(Hamming Distance)
ハミング距離とは2つの同じ長さの文字列間で異なる値の数を表します。 例をみたほうが早いでしょう。
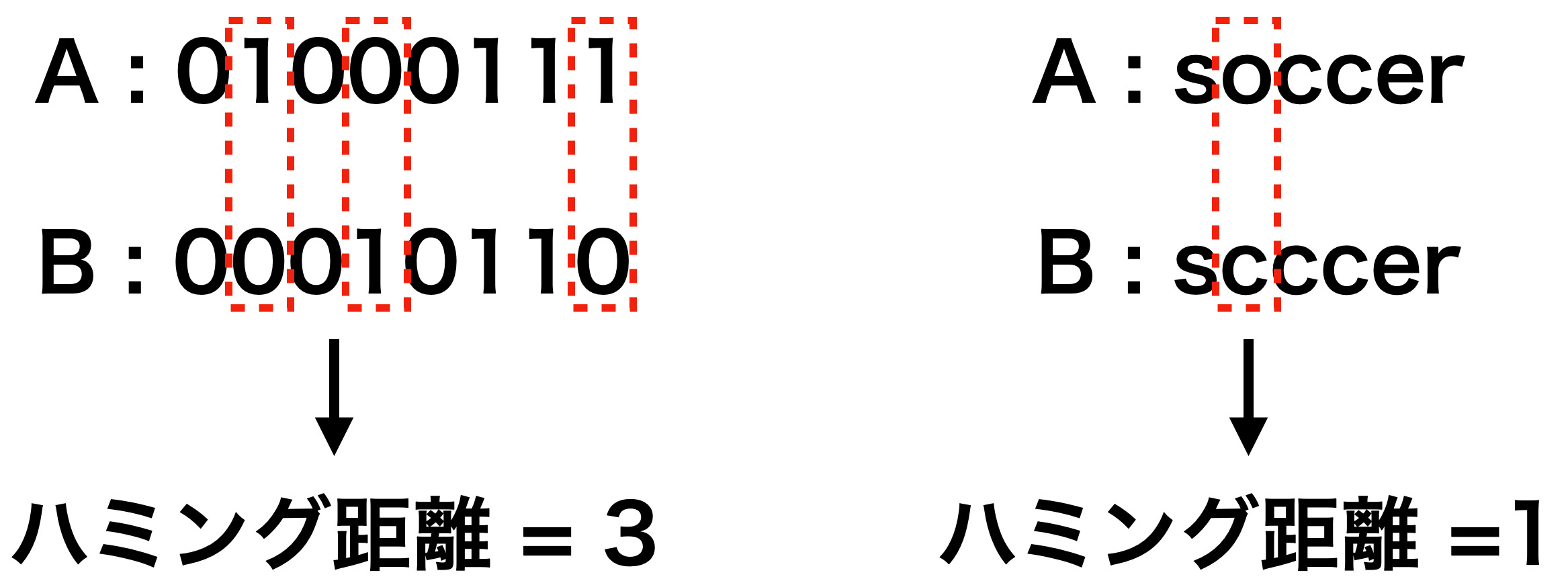
上の図のように同じ文字列で並べたときにどのくらい違うかを単純にカウントするだけです。 左の例だと3つ違うのでハミング距離=3、右の例だと1つ違うのでハミング距離1といった具合です。
pythonでの計算
pythonだとこんな感じ。
scipyに実装されてるみたいだけど、scipyの場合はハミング距離を求めてから文字列の長さで割って割合にしているみたい。
あと文字列ではなくてlist型にしないといけないみたい。
>>> from scipy.spatial import distance
>>> a = [0, 1, 0, 0, 0, 1, 1, 1]
>>> b = [0, 0, 0, 1, 0, 1, 1, 0]
>>>
>>> distance.hamming(a, b) #scipyでの計算。
0.375
>>>
>>> distance.hamming(a, b) * len(a) #カウントを知りたい場合。
3.0
listじゃなくて文字列になっている場合。
>>> a = "soccer"
>>> b = "scccer"
>>>
>>> distance.hamming(list(a), list(b)) #listに直しましょう
0.16666666666666666
>>>
>>> distance.hamming(list(a), list(b)) * len(a)
1.0
どういう時に使われるのか
コンピュータのデータ転送の際のチェックの時に使われます。 バイナリデータだから適切な感じはしますよね。 またカテゴリデータを使っている時の類似度でも使われます。 カテゴリデータ0,1で表示されるのでこれも当たり前な感じがします。
一方で問題点は同じ文字列じゃないといけないことと、文字列の違いの大きさが考慮できないことです。 違うものは違う!としかわからないのでどんくらい違うの?とかはわからんってことですね。 この辺を改良したものがレーベンシュタイン距離というものになります。 これに関してはまた別記事で紹介する予定です。