概要
Kerasを使ってVAE(Variational Autoencoder)の実装を行なっていきます。 この記事はこのチュートリアルをベースに作っています。 データセットはMNISTを使っています。
今回実装したコードは筆者のgithubにて共有しています。
VAE(Variational Autoencoder)
そもそもVAEとは何者かですが、ざっくりオートエンコーダーの一種です。 通常のオートエンコーダーとの違いは圧縮したときの潜在変数zを確率分布の形にしているというところです。 詳しい解説はこちらの記事がわかりやすかったです。 論文はこちら。
実装
それではプログラムに入っていきます。
ライブラリ
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
サンプリングレイヤー
class Sampling(layers.Layer):
def call(self, inputs):
z_mean, z_log_var = inputs
batch = tf.shape(z_mean)[0]
dim = tf.shape(z_mean)[1]
epsilon = tf.keras.backend.random_normal(shape=(batch, dim))
return z_mean + tf.exp(0.5 * z_log_var) * epsilon
この部分がVAEにおいて一番重要なレイヤーとなります。潜在変数を確率分布にしています。
エンコーダー
latent_dim = 2
encoder_inputs = keras.Input(shape=(28, 28, 1))
x = layers.Conv2D(32, 3, activation="relu", strides=2, padding="same")(encoder_inputs)
x = layers.Conv2D(64, 3, activation="relu", strides=2, padding="same")(x)
x = layers.Flatten()(x)
x = layers.Dense(16, activation="relu")(x)
z_mean = layers.Dense(latent_dim, name="z_mean")(x)
z_log_var = layers.Dense(latent_dim, name="z_log_var")(x)
z = Sampling()([z_mean, z_log_var])
encoder = keras.Model(encoder_inputs, [z_mean, z_log_var, z], name="encoder")
encoder.summary()
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 28, 28, 1)] 0
__________________________________________________________________________________________________
conv2d (Conv2D) (None, 14, 14, 32) 320 input_1[0][0]
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, 7, 7, 64) 18496 conv2d[0][0]
__________________________________________________________________________________________________
flatten (Flatten) (None, 3136) 0 conv2d_1[0][0]
__________________________________________________________________________________________________
dense (Dense) (None, 16) 50192 flatten[0][0]
__________________________________________________________________________________________________
z_mean (Dense) (None, 2) 34 dense[0][0]
__________________________________________________________________________________________________
z_log_var (Dense) (None, 2) 34 dense[0][0]
__________________________________________________________________________________________________
sampling (Sampling) (None, 2) 0 z_mean[0][0]
z_log_var[0][0]
==================================================================================================
Total params: 69,076
Trainable params: 69,076
Non-trainable params: 0
__________________________________________________________________________________________________
エンコーダー部分です。最後の層に先ほど作ったサンプリングレイヤーを追加しています。
デコーダー
latent_inputs = keras.Input(shape=(latent_dim,))
x = layers.Dense(7 * 7 * 64, activation="relu")(latent_inputs)
x = layers.Reshape((7, 7, 64))(x)
x = layers.Conv2DTranspose(64, 3, activation="relu", strides=2, padding="same")(x)
x = layers.Conv2DTranspose(32, 3, activation="relu", strides=2, padding="same")(x)
decoder_outputs = layers.Conv2DTranspose(1, 3, activation="sigmoid", padding="same")(x)
decoder = keras.Model(latent_inputs, decoder_outputs, name="decoder")
decoder.summary()
__________________________________________________________________________________________________
Model: "decoder"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 2)] 0
_________________________________________________________________
dense_1 (Dense) (None, 3136) 9408
_________________________________________________________________
reshape (Reshape) (None, 7, 7, 64) 0
_________________________________________________________________
conv2d_transpose (Conv2DTran (None, 14, 14, 64) 36928
_________________________________________________________________
conv2d_transpose_1 (Conv2DTr (None, 28, 28, 32) 18464
_________________________________________________________________
conv2d_transpose_2 (Conv2DTr (None, 28, 28, 1) 289
=================================================================
Total params: 65,089
Trainable params: 65,089
Non-trainable params: 0
_________________________________________________________________
そしてデコーダー部分です。
VAE
class VAE(keras.Model):
def __init__(self, encoder, decoder, **kwargs):
super(VAE, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
self.total_loss_tracker = keras.metrics.Mean(name="total_loss")
self.reconstruction_loss_tracker = keras.metrics.Mean(name="reconstruction_loss")
self.kl_loss_tracker = keras.metrics.Mean(name="kl_loss")
@property
def metrics(self):
return [
self.total_loss_tracker,
self.reconstruction_loss_tracker,
self.kl_loss_tracker,
]
def predict(self, x):
z_mean, _, _ = self.encoder.predict(x)
y = self.decoder.predict(z_mean)
return y
def train_step(self, data):
with tf.GradientTape() as tape:
z_mean, z_log_var, z = self.encoder(data)
reconstruction = self.decoder(z)
reconstruction_loss = tf.reduce_mean(
tf.reduce_sum(
keras.losses.binary_crossentropy(data, reconstruction), axis=(1, 2)
)
)
kl_loss = -0.5 * (1 + z_log_var - tf.square(z_mean) - tf.exp(z_log_var))
kl_loss = tf.reduce_mean(tf.reduce_sum(kl_loss, axis=1))
total_loss = reconstruction_loss + kl_loss
grads = tape.gradient(total_loss, self.trainable_weights)
self.optimizer.apply_gradients(zip(grads, self.trainable_weights))
self.total_loss_tracker.update_state(total_loss)
self.reconstruction_loss_tracker.update_state(reconstruction_loss)
self.kl_loss_tracker.update_state(kl_loss)
return {
"loss": self.total_loss_tracker.result(),
"reconstruction_loss": self.reconstruction_loss_tracker.result(),
"kl_loss": self.kl_loss_tracker.result(),
}
上記で作ったエンコーダーとデコーダーを使ってVAEを構築しています。
学習
(x_train, _), (x_test, _) = keras.datasets.mnist.load_data()
mnist_digits = np.concatenate([x_train, x_test], axis=0)
mnist_digits = np.expand_dims(mnist_digits, -1).astype("float32") / 255
vae = VAE(encoder, decoder)
vae.compile(optimizer=keras.optimizers.Adam())
history = vae.fit(mnist_digits, epochs=30, batch_size=128)
以下、学習過程です。
Epoch 1/30
547/547 [==============================] - 50s 91ms/step - loss: 254.0731 - reconstruction_loss: 207.7044 - kl_loss: 2.8044
Epoch 2/30
547/547 [==============================] - 67s 123ms/step - loss: 175.8866 - reconstruction_loss: 165.7936 - kl_loss: 4.9872
Epoch 3/30
547/547 [==============================] - 78s 142ms/step - loss: 161.9824 - reconstruction_loss: 155.5914 - kl_loss: 5.4123
...
...
...
Epoch 28/30
547/547 [==============================] - 68s 125ms/step - loss: 147.9350 - reconstruction_loss: 141.6587 - kl_loss: 6.3569
Epoch 29/30
547/547 [==============================] - 72s 132ms/step - loss: 147.6914 - reconstruction_loss: 141.5113 - kl_loss: 6.3681
Epoch 30/30
547/547 [==============================] - 71s 129ms/step - loss: 147.4736 - reconstruction_loss: 141.3945 - kl_loss: 6.3814
学習の結果をプロットしてみましょう。
row = 1
col = 3
fig, ax = plt.subplots(row, col, figsize=(15,4))
ax[0].plot(history.history["loss"])
ax[0].set_ylabel('loss')
ax[0].set_xlabel('epoch')
ax[1].plot(history.history["reconstruction_loss"])
ax[1].set_ylabel('reconstruction_loss')
ax[1].set_xlabel('epoch')
ax[2].plot(history.history["kl_loss"])
ax[2].set_ylabel('kl_loss')
ax[2].set_xlabel('epoch')
plt.show()
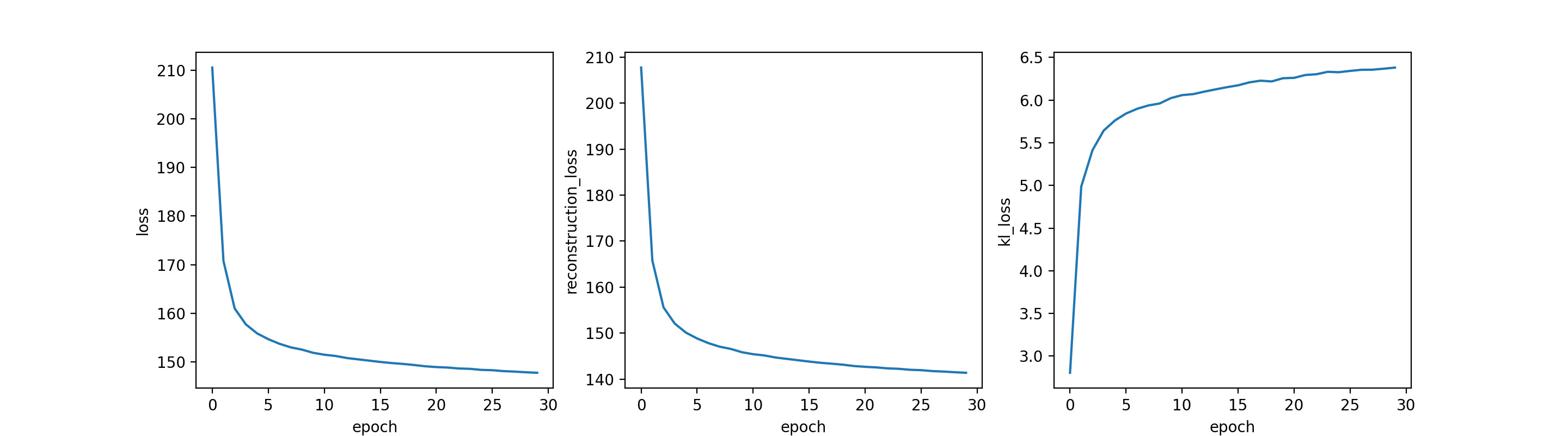
いい感じに学習できてそうですね。
画像を復元してみる
それでは学習したモデルを使って画像を復元してみましょう。
vae = VAE(encoder, decoder)
vae.compile(optimizer=keras.optimizers.Adam())
vae.built = True
vae.load_weights("vae.h5")
index = 200
x = mnist_digits[index]
x = np.expand_dims(x, 0)
x_decode = vae.predict(x)
row = 1
col = 2
fig, ax = plt.subplots(row, col, figsize=(10,4))
ax[0].imshow(x[0], cmap="Greys_r")
ax[0].set_title('raw')
ax[1].imshow(x_decode[0], cmap="Greys_r")
ax[1].set_title('result')
plt.show()
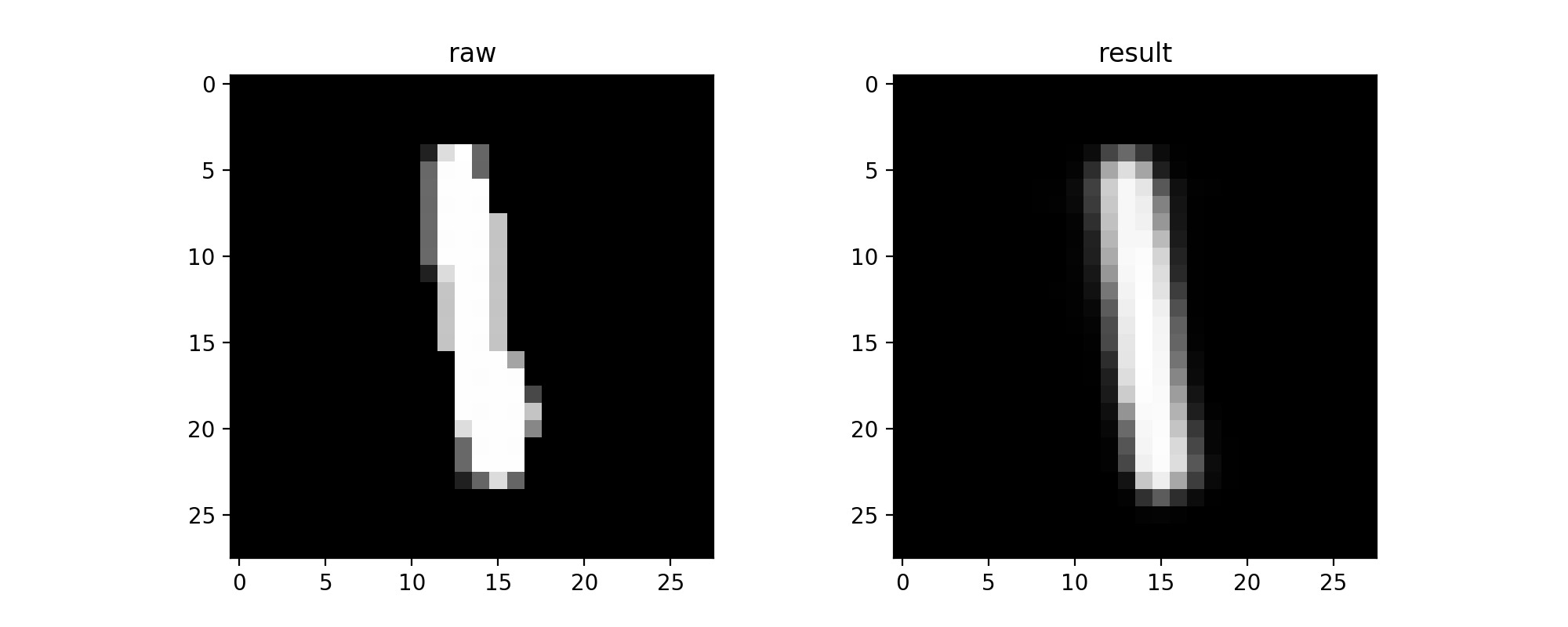
いい感じです。
デコーダーを使い、潜在変数から画像を生成
ここではデコーダーを使って画像を生成していきます。潜在変数z[0],z[1]に対してそれぞれ0~1の範囲で変えていきそれをグリッドの形で表示します。
def plot_latent_space(vae, n=30, figsize=15):
digit_size = 28
scale = 1.0
figure = np.zeros((digit_size * n, digit_size * n))
grid_x = np.linspace(-scale, scale, n)
grid_y = np.linspace(-scale, scale, n)[::-1]
for i, yi in enumerate(grid_y):
for j, xi in enumerate(grid_x):
z_sample = np.array([[xi, yi]])
x_decoded = vae.decoder.predict(z_sample)
digit = x_decoded[0].reshape(digit_size, digit_size)
figure[
i * digit_size : (i + 1) * digit_size,
j * digit_size : (j + 1) * digit_size,
] = digit
plt.figure(figsize=(figsize, figsize))
start_range = digit_size // 2
end_range = n * digit_size + start_range
pixel_range = np.arange(start_range, end_range, digit_size)
sample_range_x = np.round(grid_x, 1)
sample_range_y = np.round(grid_y, 1)
plt.xticks(pixel_range, sample_range_x)
plt.yticks(pixel_range, sample_range_y)
plt.xlabel("z[0]")
plt.ylabel("z[1]")
plt.imshow(figure, cmap="Greys_r")
plt.show()
plot_latent_space(vae)

エンコーダーを使い、画像を潜在変数にする
ここではエンコーダーを使って画像を潜在変数zに圧縮していきます。そして圧縮した潜在変数をターゲットごとに可視化していきます。
def plot_label_clusters(vae, data, labels):
z_mean, _, _ = vae.encoder.predict(data)
plt.figure(figsize=(12, 10))
plt.scatter(z_mean[:, 0], z_mean[:, 1], c=labels)
plt.colorbar()
plt.xlabel("z[0]")
plt.ylabel("z[1]")
plt.show()
(x_train, y_train), _ = keras.datasets.mnist.load_data()
x_train = np.expand_dims(x_train, -1).astype("float32") / 255
plot_label_clusters(vae, x_train, y_train)
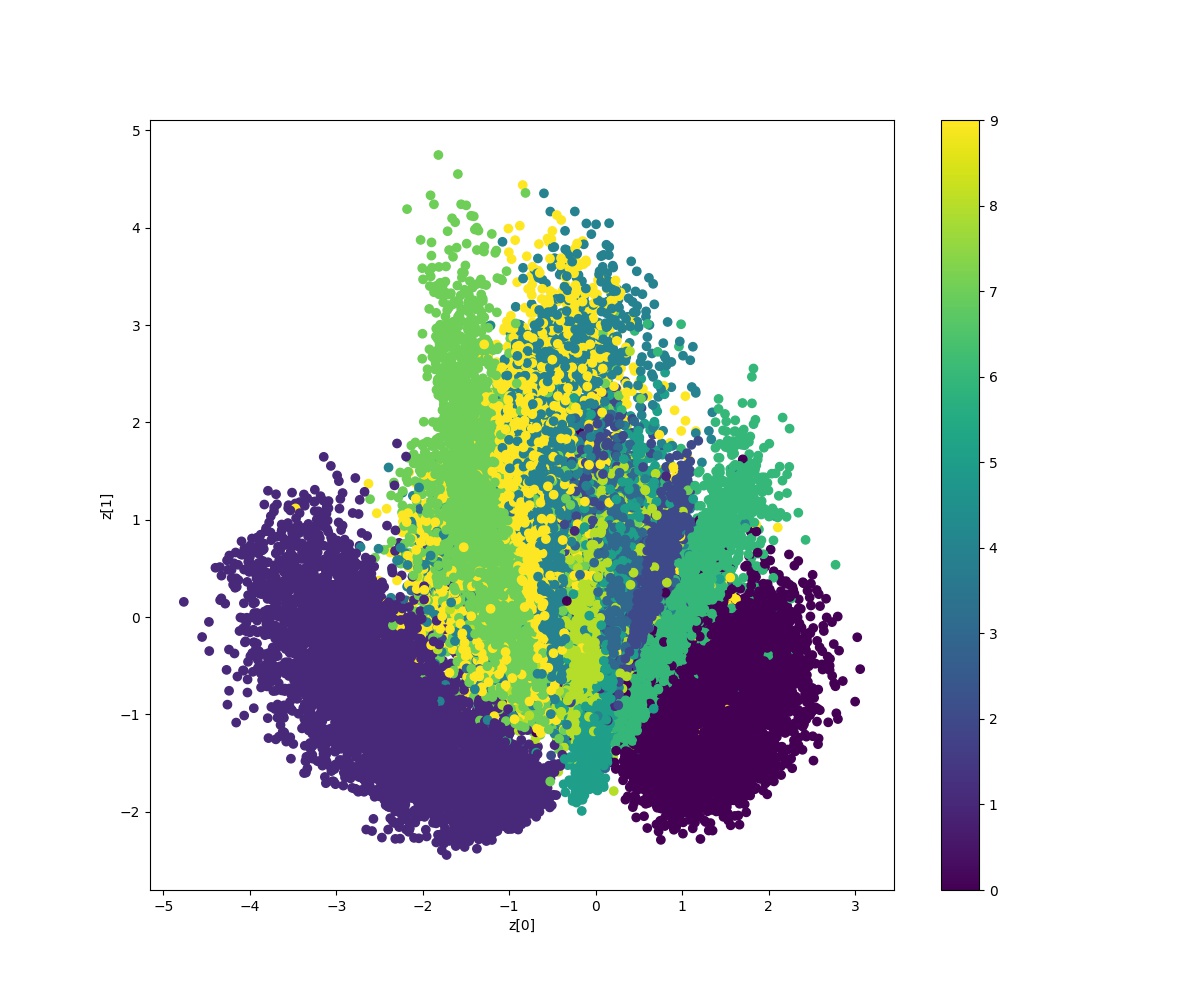
潜在変数として圧縮されたものがターゲットごとに分布されてることがわかりますね。
最後に
kerasを用いたVAEの実装を行なった。以上。