one-hotエンコーディングとは?
one-hotエンコーディングとはカテゴリデータに対する処理の一つです。
カテゴリデータは数値データではないためそのままでは機械学習に応用することができません。
そこでカテゴリごとで特徴量として作成して、それに該当するかどうかの0,1で数値データにしていきます。
これがone-hotエンコーディングです。
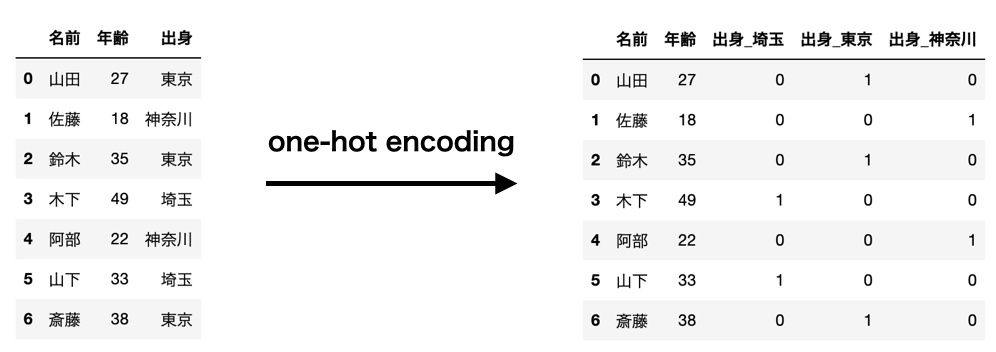
以下の図はその一例です。
このように「出身」というカテゴリデータを0,1にして特徴量していきます。
one-hotエンコーディングをする方法は2つあります。
一つはpandasのpd.get_dummiesを使う方法。
もう一つはscikit-learnにあるOneHotEncoderを使う方法です。
ずばりどちらを使うべき?
結論からいうとOneHotEncoderをおすすめしたいです。
理由は学習のためのトレインデータと本番システムで使うデータで、カテゴリの中身が少し変わってしまう可能性あるからです。
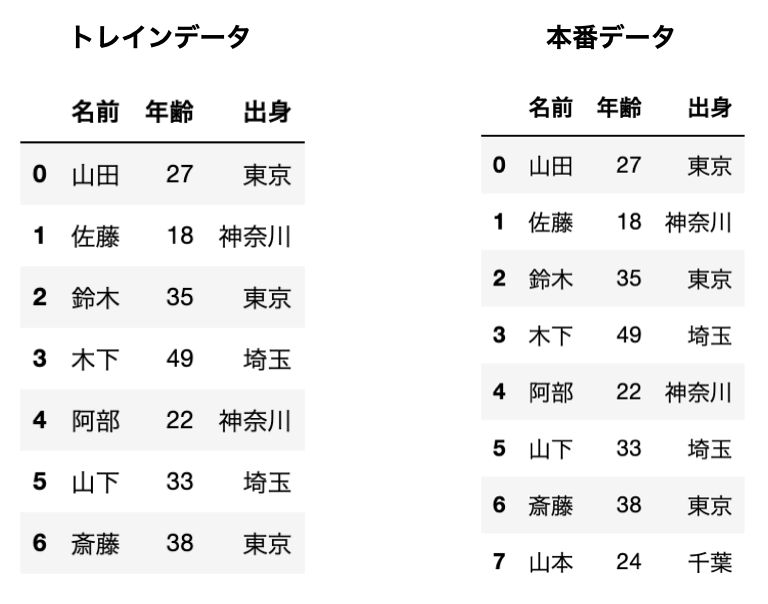
例えば以下のようにトレインデータには["東京", "神奈川", "埼玉"]しかなかったのに、本番データでは["千葉"]というデータが紛れこんでいる場合のことです。
(アンチ千葉ではありません)
ではこの違いがどのように影響してくるのでしょうか。コードを見ながら確認していきましょう。
サンプルデータを用意しておきます。
import pandas as pd
# トレインデータ
data_1 = [["山田", 27, "東京"],
["佐藤", 18, "神奈川"],
["鈴木", 35, "東京"],
["木下", 49, "埼玉"],
["阿部", 22, "神奈川"],
["山下", 33, "埼玉"],
["斎藤", 38, "東京"]]
# 学習データ
data_2 = [["山田", 27, "東京"],
["佐藤", 18, "神奈川"],
["鈴木", 35, "東京"],
["木下", 49, "埼玉"],
["阿部", 22, "神奈川"],
["山下", 33, "埼玉"],
["斎藤", 38, "東京"],
["山本", 24, "千葉"]]
df_1 = pd.DataFrame(data_1, columns=["名前", "年齢", "出身"])
df_2 = pd.DataFrame(data_2, columns=["名前", "年齢", "出身"])
pandasのget_dummies()の場合
まずget_dummies()で処理してみます。
pd.get_dummies(df_1, columns=['出身'])
pd.get_dummies(df_2, columns=['出身'])
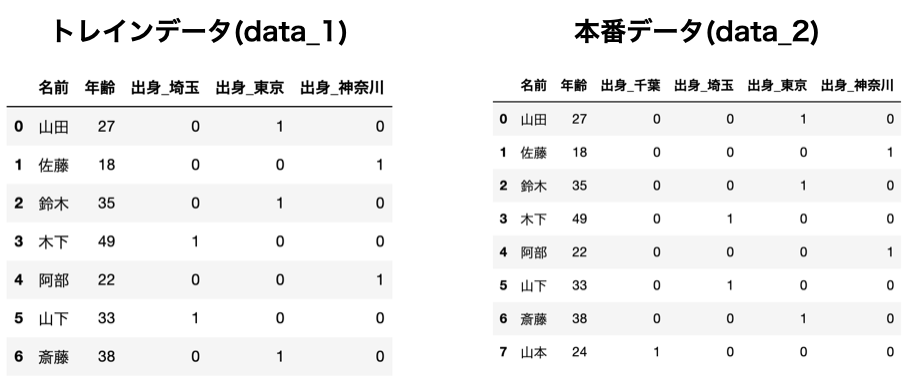
トレインデータでは["出身_東京", "出身_神奈川", "出身_埼玉"]という特徴量ができたのに対して、本番データではそれに["出身_千葉"]も特徴量としてできています。
要するにトレインデータより、本番データの方が特徴量が多くなってしまっています。
トレインデータを使って学習させたモデルを本番として使うためには、特徴量の数が同じでなくてはいけません。
get_dummies()ではこのようにトレインデータと本番データの特徴量が変わってしまう問題があります。
scikit-learnのOneHotEncoderの場合
それではOneHotEncoderを見てみましょう。
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder(handle_unknown='ignore') #"ignore"にするの大事
encoder.fit(df_1["出身"].values.reshape(-1, 1))
encoder_data_1 = encoder.transform(df_1["出身"].values.reshape(-1, 1))
encoder_data_2 = encoder.transform(df_2["出身"].values.reshape(-1, 1))
encoder_data_1_df = pd.DataFrame(encoder_data_1.toarray().astype('int64'), columns=encoder.categories_)
encoder_data_2_df = pd.DataFrame(encoder_data_2.toarray().astype('int64'), columns=encoder.categories_)
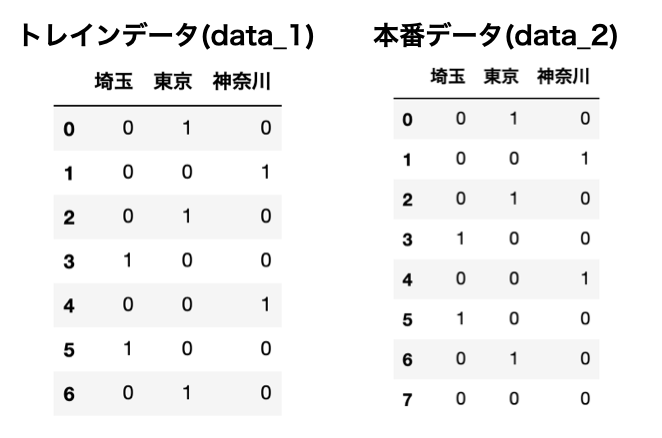
このようにOneHotEncoderの場合は、トレインデータも本番データも同じ数の特徴量にすることができました。
最後に
千葉消すくらいなら手動ルールベースでよくない?と思うかもしれません(アンチ千葉ではありません)。 ただ予期せぬカテゴリデータが出てきたり、逆にデータが少なかったりするとルールベースで対応するのはかなり困難かと思います。
一方で解析などを行う際で今後その変換処理を使わない場合はget_dummies()を使う方が楽なときもありますので、適宜使い分けられるとよいかもしれません(本末転倒)。