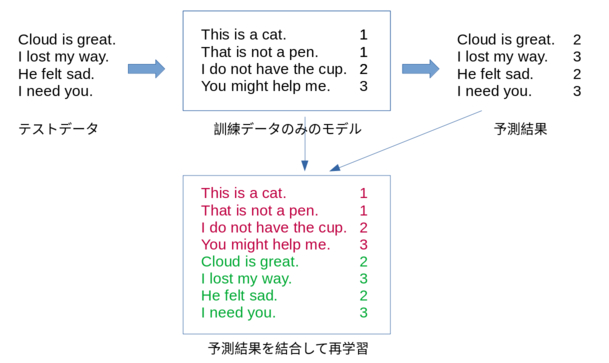
疑似ラベリングとは学習時にテストデータの一部を予測したものを含めて学習し、このモデルを使って再度テストデータの全体を学習することです。以下に概要図を書きました。
実装
simpletransformersを使ったテキスト多クラス分類問題を想定しています。
なお実装の参考はこちらです。
参考記事中では疑似ラベリングに使うデータをtest.csvからランダムに選出しています。
しかしここでは予測確度が0.90を超えたデータの数をカウントしてtest.csvの98%以上を占めるまで擬似ラベリングを繰り返すという実装にしています。
これは予測確度が低いものを疑似ラベリングに含めると誤った方向に学習が進む可能性が高いためです。
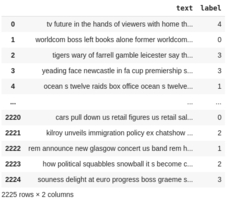
なおここで使うデータの形式はsimpletransformersが使う以下のようなデータ形式に従っています。
train = pd.read_csv('train.csv') # 任意の訓練データセット
test = pd.read_csv('test.csv') # 任意のテストデータ
count = 0
def pseudo_labeling(model, train, test):
if count == 0:
model.train_model(train)
else:
model = ClassificationModel('bert', 'outputs-1/', args={})
pseudo_labels, raw_outputs = model.predict(test['text'])
probabilities = softmax(raw_outputs, axis=1)
threshold = 0.90
exceeded = np.array([*map(lambda x: max(x), probabilities)]) > threshold # 閾値を超えたかどうかTrue/Falseのリスト
percentage = sum(exceeded) / len(probabilities) # 閾値を超えたものの割合
print('The percentage of predictions that the probability is over ' + str(threshold * 100) + '%: ', percentage)
pl_indices = np.where(exceeded == True)
pl_test = pd.DataFrame()
for i, x in test.iterrows():
if i in pl_indices[0]:
pl_test = pl_test.append({'label': pseudo_labels[i], 'text': x['text']}, ignore_index=True)
print(len(pl_test[pl_test.label == 0]), len(pl_test[pl_test.label == 1]), len(pl_test[pl_test.label == 2]), len(pl_test[pl_test.label == 3]))
augemented_train = pd.concat([pl_test, train])
augemented_train=augemented_train[augemented_train.columns[::-1]]
return shuffle(augemented_train), percentage
params = {
"output_dir": "outputs-1/",
"max_seq_length": 512,
"train_batch_size": 8,
"eval_batch_size": 8,
"num_train_epochs": 5,
"learning_rate": 1e-5,
"manual_seed":SEED,
'overwrite_output_dir': True
}
model = ClassificationModel('bert', 'bert-base-cased', num_labels=4, args=params, use_cuda=True)
percentage = 0
while percentage < 0.98: # test.csvのうち予測確度が0.90を超えるものが98%以上になるまで繰り返す
X_train, percentage = pseudo_labeling(model, X_train, test)
model.train_model(X_train)
count += 1