概要
自作方法
とりあえずこんな感じで書いていけばOK
import gym
class MyEnv(gym.Env):
def __init__(self):
ACTION_NUM=3 #アクションの数が3つの場合
self.action_space = gym.spaces.Discrete(ACTION_NUM)
#状態が3つの時で上限と下限の設定と仮定
LOW=[0,0,0]
HIGH=[1,1,1]
self.observation_space = gym.spaces.Box(low=LOW, high=HIGH)
def reset(self):
return observation
def step(self, action_index):
return observation, reward, done, {}
def render(self):
pass
用意する必要な関数は以下の通り。
| 関数 | 役割 |
|---|---|
| reset | 初期化処理。observation(状態)を返す |
| step | stepを一つ進める処理。この中で報酬の計算と終了判定を行う。observation(状態) reward(報酬) done(終了フラグ)を返す |
| render | 描画処理 |
用意する必要な変数は以下の通り。
| 変数 | 役割 |
|---|---|
| action_space | 行動の数を定義 |
| observation_space | 状態空間の定義。状態における最小値と最大値を設定。 |
とりあえず自作してみる
自作環境の概要
今回作成する環境はボールとゴールを用意してゴールにたどり着いたらクリアという単純なものにします。要件としては大体以下のような感じ。
- ボールとゴールの位置はランダムで初期化をする
- ゴールの範囲を設定してその範囲に到達したらクリア
- ボールがとりうるアクションは8つあり、上下左右と斜めの8つである
- 状態はボールとゴールの角度のみを利用。範囲は
-pi < θ <= pi - 報酬は1step前のゴールまでの距離と現在のゴールまでの距離の差を利用。要するにアクションした結果どれだけゴールに近づいたかを報酬として与えている
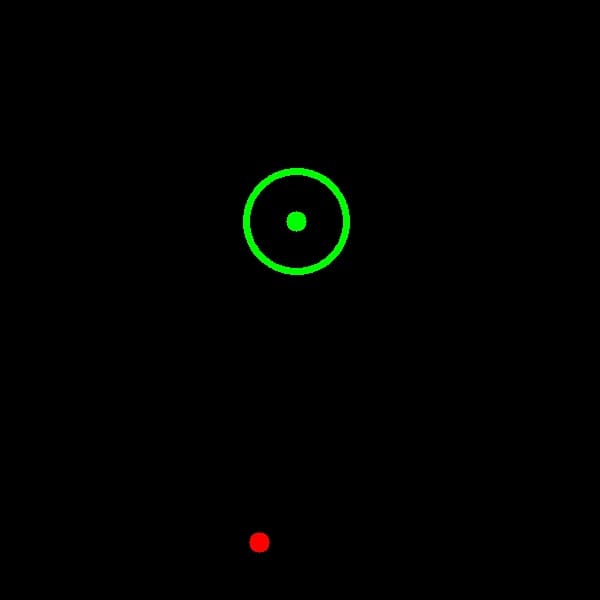
環境のイメージは以下の図をみてください。緑がゴールで、赤がボールです。
フォルダ構成は以下の通り・
$ tree .
.
├── environment.py
├── test.py
└── train.py
コード
まずは一番重要なenvironment.py
import gym
import numpy as np
import cv2
class MyEnv(gym.Env):
def __init__(self):
self.WINDOW_SIZE = 600 #画面サイズの決定
self.ACTION_MAP = np.array([[1, 0], [1, 1], [0, 1], [-1, 1], [-1, 0], [-1, -1], [0, -1], [1, -1]]) #アクションの用意
self.GOAL_RANGE = 50 #ゴールの範囲設定
# アクション数定義
ACTION_NUM = 8
self.action_space = gym.spaces.Discrete(ACTION_NUM)
# 状態の範囲を定義
LOW = np.array([-np.pi])
HIGH = np.array([np.pi])
self.observation_space = gym.spaces.Box(low=LOW, high=HIGH)
self.reset()
def reset(self):
# ボールとゴールの位置をランダムで初期化
self.ball_position = np.array([np.random.randint(0, self.WINDOW_SIZE), np.random.randint(0, self.WINDOW_SIZE)])
self.goal_position = np.array([np.random.randint(0, self.WINDOW_SIZE), np.random.randint(0, self.WINDOW_SIZE)])
# 状態の作成
vec = self.ball_position - self.goal_position
observation = np.arctan2(vec[0], vec[1]) # 角度の計算
observation = np.array([observation])
self.before_distance = np.linalg.norm(vec)
return observation
def step(self, action_index):
action = self.ACTION_MAP[action_index]
self.ball_position = self.ball_position-action
# 状態の作成
vec = self.ball_position - self.goal_position
observation = np.arctan2(vec[0], vec[1]) # 角度の計算
observation = np.array([observation])
# 報酬の計算
distance = np.linalg.norm(vec) # 距離の計算
reward = self.before_distance - distance # どれだけゴールに近づいたか
# 終了判定
done = False
if distance < self.GOAL_RANGE:
done = True
self.before_distance = distance
return observation, reward, done, {}
def render(self):
# opencvで描画処理してます
img = np.zeros((self.WINDOW_SIZE, self.WINDOW_SIZE, 3)) #画面初期化
cv2.circle(img, tuple(self.goal_position), 10, (0, 255, 0), thickness=-1) #ゴールの描画
cv2.circle(img, tuple(self.goal_position), self.GOAL_RANGE, color=(0,255,0), thickness=5) #ゴールの範囲の描画
cv2.circle(img, tuple(self.ball_position), 10, (0, 0, 255), thickness=-1) #ボールの描画
cv2.imshow('image', img)
cv2.waitKey(1)
続いて学習するためのスクリプトtrain.py。今回はstable-baselinesに実装されているDDQNを用いる。
from stable_baselines.deepq.policies import MlpPolicy
from stable_baselines import DQN
from stable_baselines.common.callbacks import CheckpointCallback
from environment import MyEnv
env = MyEnv()
model = DQN(MlpPolicy, env, verbose=1, tensorboard_log="log")
print('start learning')
checkpoint_callback = CheckpointCallback(save_freq=500, save_path='./save_weights/', name_prefix='rl_model')
model.learn(total_timesteps=10000, callback=checkpoint_callback)
print('finish learning')
最後にtest.py。学習した重みを用いて実際の挙動を確認するもの。
from stable_baselines.deepq.policies import MlpPolicy
from stable_baselines import DQN
from environment import MyEnv
env = MyEnv()
model = DQN(MlpPolicy, env, verbose=1, tensorboard_log="log")
# pathを指定して任意の重みをロードする
model = DQN.load("./save_weights/rl_model_10000_steps")
# 10回試行する
for i in range(10):
obs = env.reset()
while True:
action, _states = model.predict(obs)
obs, rewards, dones, info = env.step(action)
env.render()
if dones:
break
学習してみる
プログラムが用意できたら早速学習してみましょう。
$ python train.py
学習を終えると以下のようなフォルダ構成になるはずです。logにはtensorboardで確認できる学習データがあります。save_weightsには500stepごとに保存された重みがあります。
$ tree .
.
├── environment.py
├── log
│ └── DQN_1
│ └── events.out.tfevents.1600437740.koki-4.local
├── save_weights
│ ├── rl_model_10000_steps.zip
│ ├── rl_model_1000_steps.zip
│ ├── rl_model_1500_steps.zip
│ ├── rl_model_2000_steps.zip
│ ├── rl_model_2500_steps.zip
│ ├── rl_model_3000_steps.zip
│ ├── rl_model_3500_steps.zip
│ ├── rl_model_4000_steps.zip
│ ├── rl_model_4500_steps.zip
│ ├── rl_model_5000_steps.zip
│ ├── rl_model_500_steps.zip
│ ├── rl_model_5500_steps.zip
│ ├── rl_model_6000_steps.zip
│ ├── rl_model_6500_steps.zip
│ ├── rl_model_7000_steps.zip
│ ├── rl_model_7500_steps.zip
│ ├── rl_model_8000_steps.zip
│ ├── rl_model_8500_steps.zip
│ ├── rl_model_9000_steps.zip
│ └── rl_model_9500_steps.zip
├── test.py
└── train.py
学習結果の確認
それでは学習結果を確認してみましょう!まずはtensorboardを使って学習曲線をみてみます。
$ tensorboard --logdir log
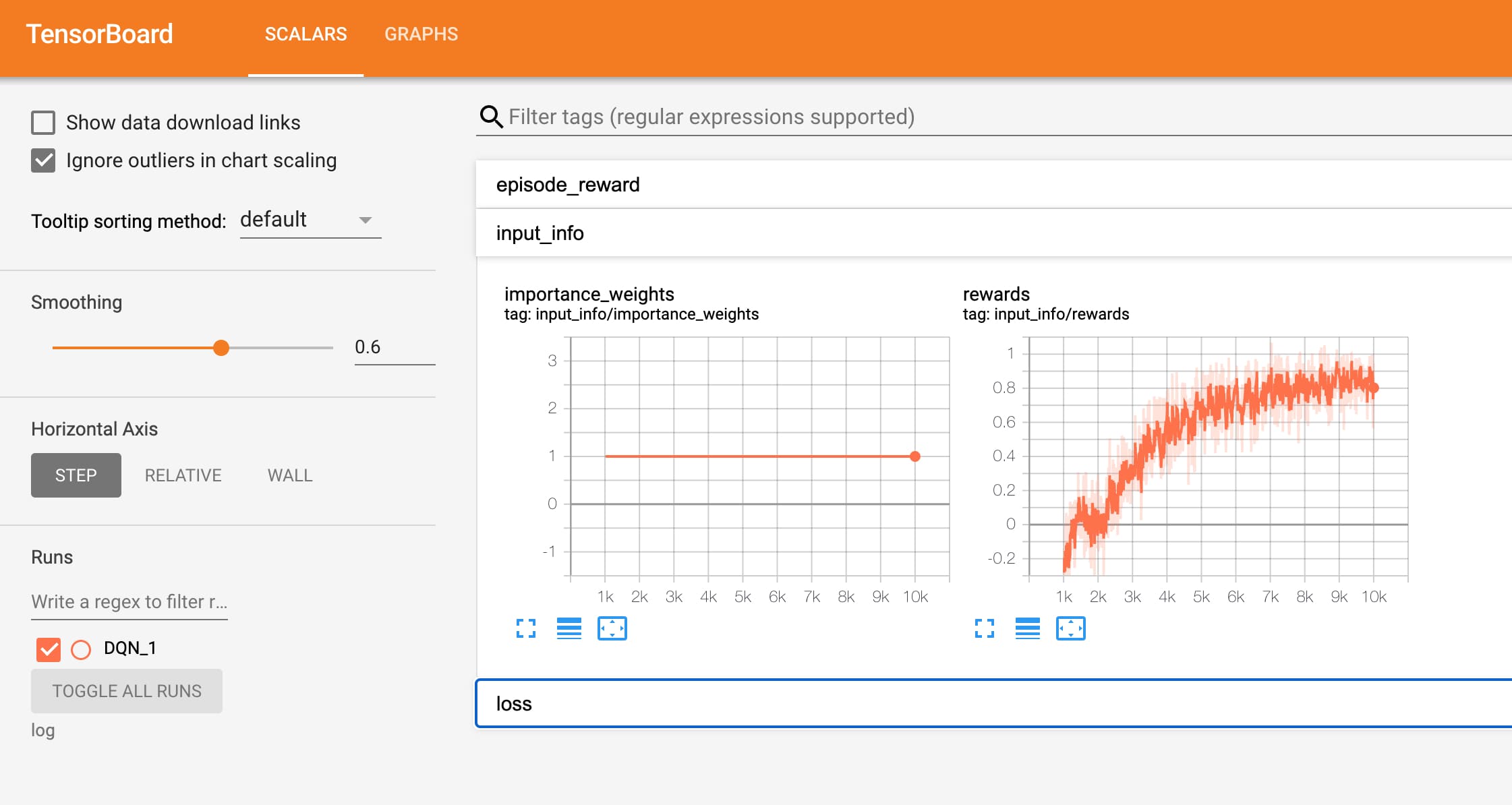
それっぽく学習できている模様。
続いて実際に動かしてみます。しょぼそうなrl_model_500_stepsからやってみます。test.pyの中でpathを変えてやってみてください。
$ python test.py
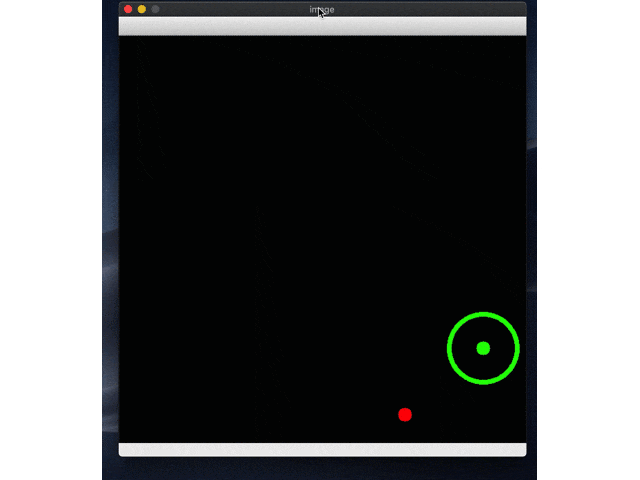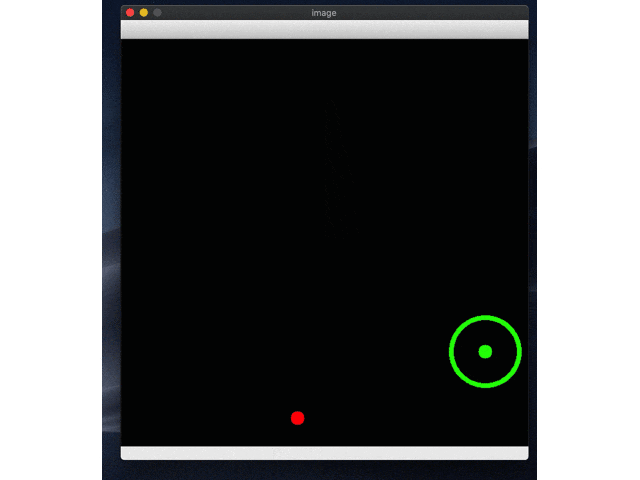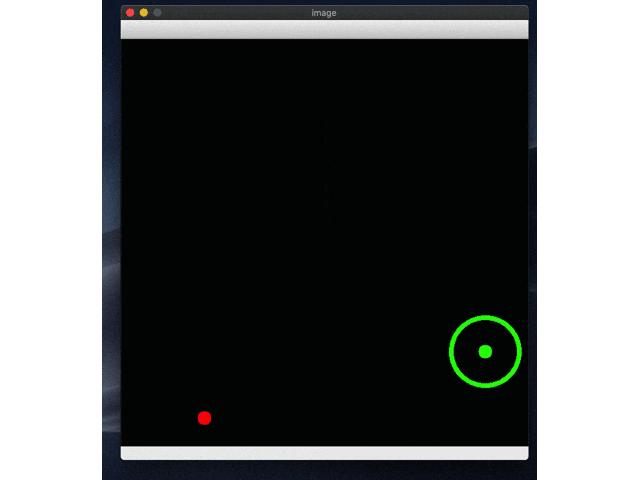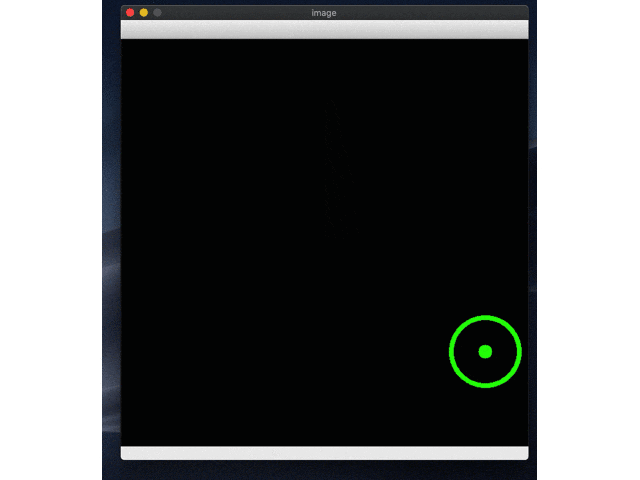
はい、どっかいったー。Ctr+Cで止めないと無限ループなので止めてください。
続いてrl_model_10000_stepsにして試す。
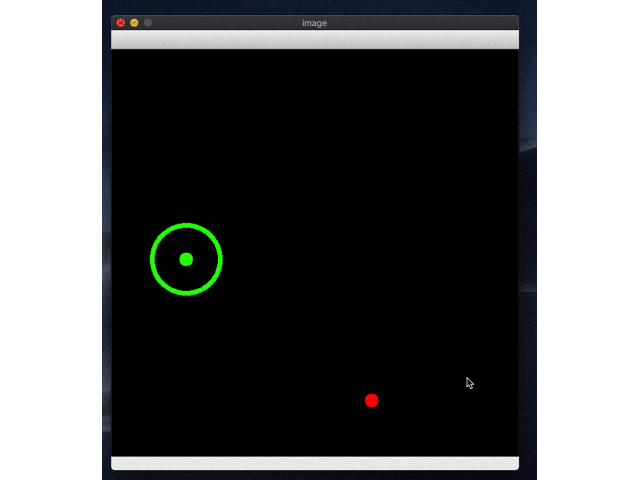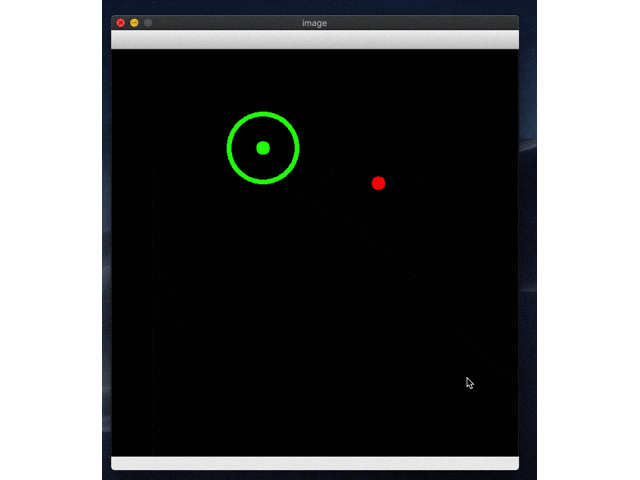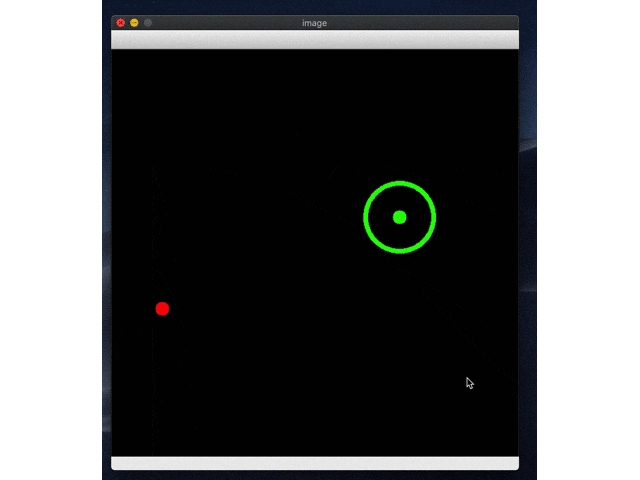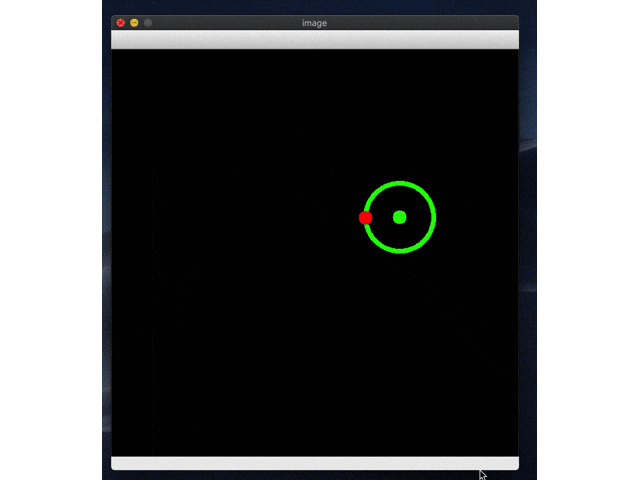
こっちはしっかりゴールにたどり着いてますね!めでたしめでたし。
最後に
今回はgym形式での自作環境を作り学習させていきました。無事うまくできてよかったです。なんか面白い環境思いついたらぜひ自作してみてくださいorご連絡ください!それでは。