やること
stable-baselinesを使ってDDQNを動かします。環境としてはGymのCartPoleを利用していきます。
stable-baselinesのインストールはこちらの記事から。
サンプルコード
学習
import gym
from stable_baselines.common.vec_env import DummyVecEnv
from stable_baselines.deepq.policies import MlpPolicy
from stable_baselines import DQN
env = gym.make('CartPole-v1')
model = DQN(MlpPolicy, env, verbose=1, tensorboard_log="log") #tensorboard_logはデフォルトではNone
model.learn(total_timesteps=15000)
モデル保存
model.save("deepq_cartpole")
モデル読み込み
model = DQN.load("deepq_cartpole")
モデルを試す
obs = env.reset()
while True:
action, _states = model.predict(obs)
obs, rewards, dones, info = env.step(action)
env.render()
if dones:
break
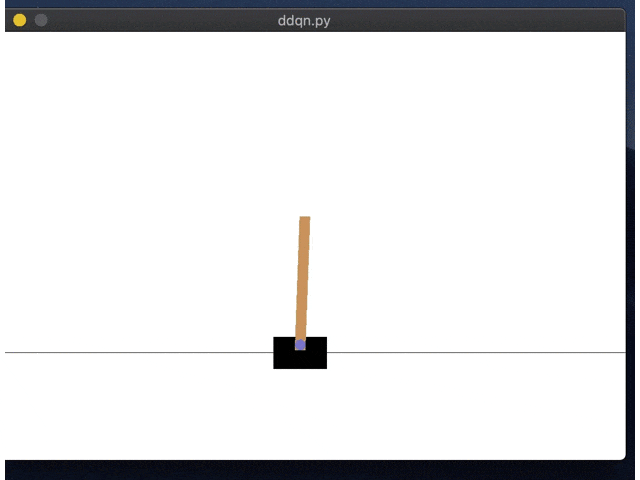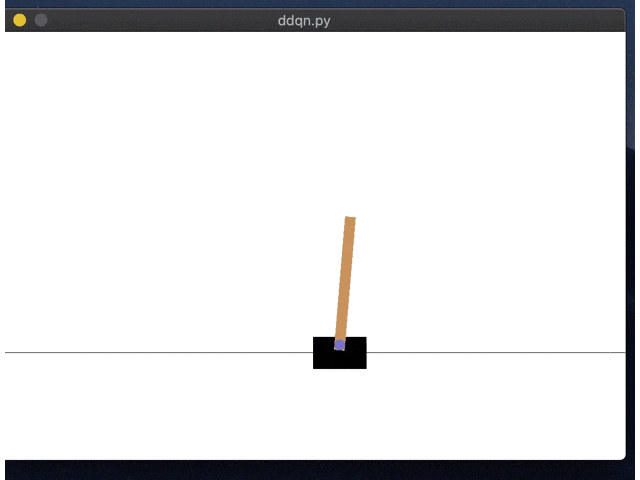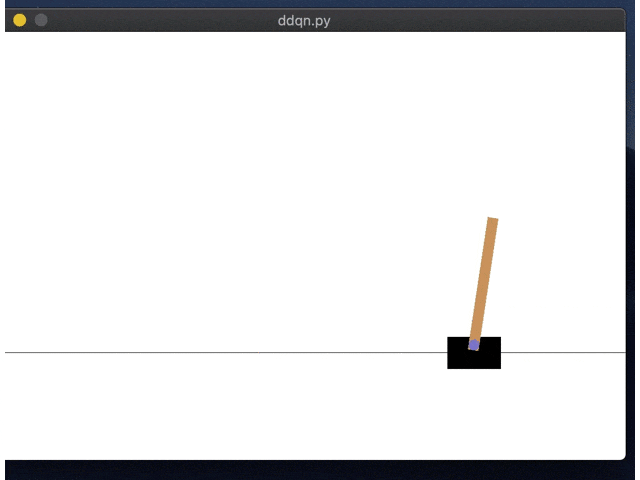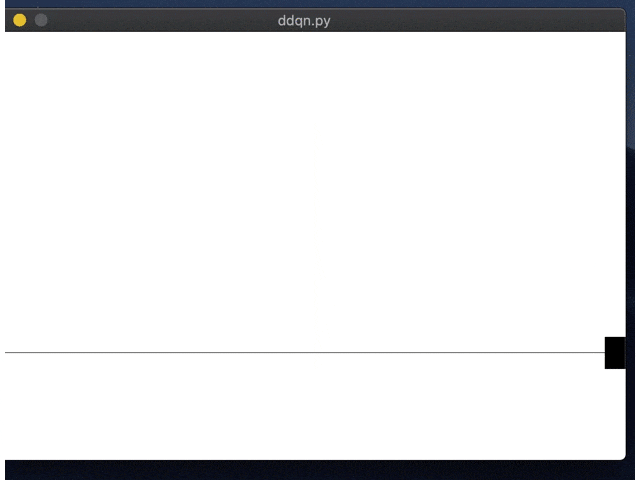
右にいくように学習してしまってますね。
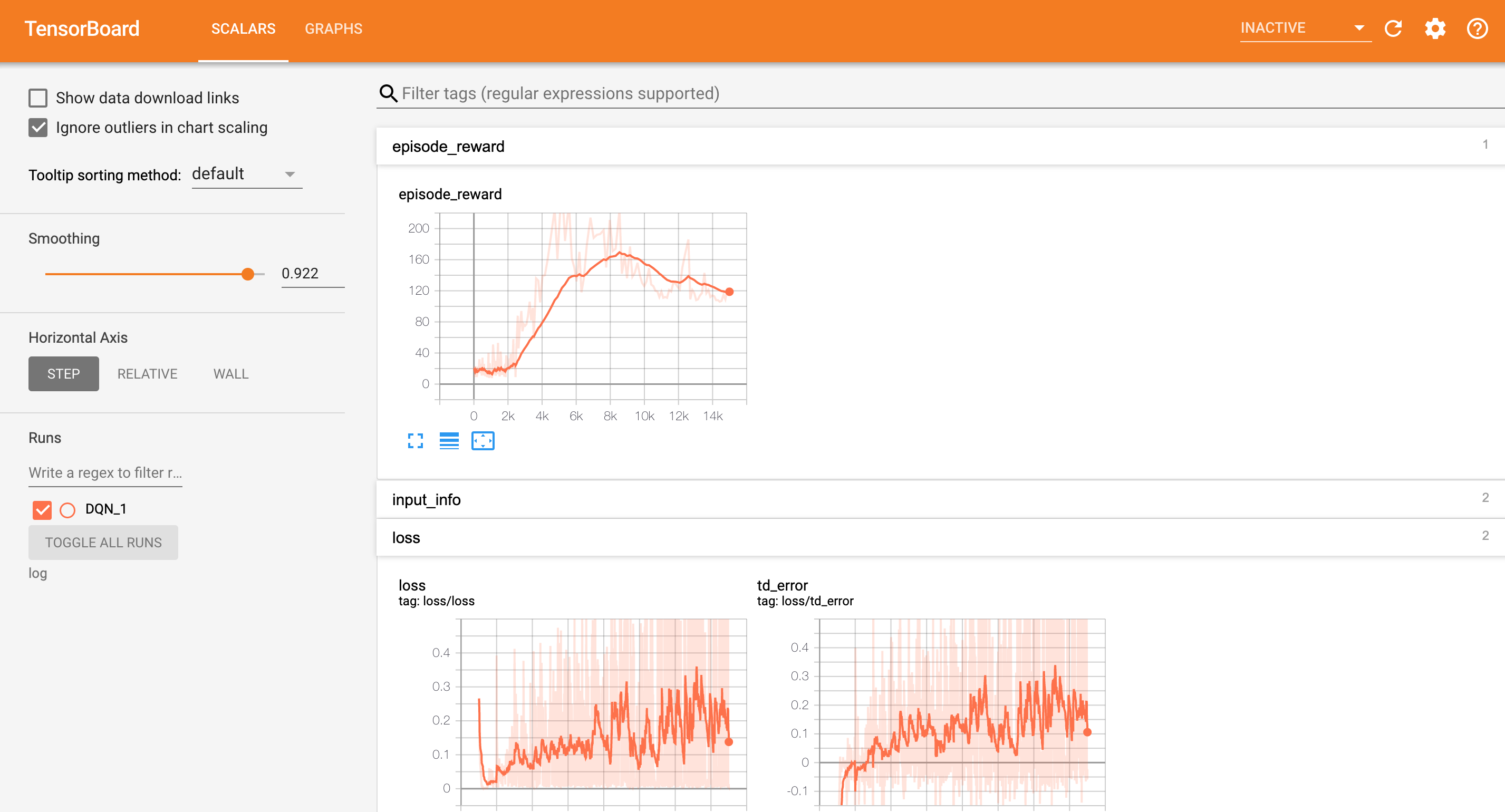
学習結果を確認してみる
$ tensorboard --logdir log
その他アルゴリズム
別記事ではその他のアルゴリズムも動かしていますのでぜひご覧ください!
- A2C
- ACER
- ACKTR
- DDPG
- DDQN(この記事)
- GAIL
- HER
- PPO
- SAC
- TD3
- TRPO