テキスト分類を行う際、教師データを増やすために水増しをすることは非常に重要です。
テキストデータ水増しの手法として、Data Augmentation in NLPという記事には
- ソーシラス(単語の上位/下位概念や類義語、反義語を持つ辞書)
- 単語埋め込み(単語を数値列で表す)
- 逆翻訳
- 文脈を意識した単語埋め込み
- テキスト生成
が紹介されています。この記事ではこの中から逆翻訳についてコードと共に書いていきます。
逆翻訳とは
逆翻訳は元のテキストを一度別の言語に翻訳してからまた英語に戻すことで似てるけど少し違う文章を生成してデータを水増しするものです。
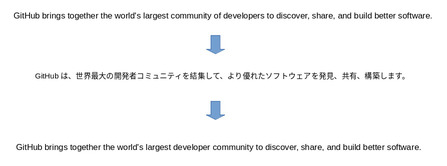
雑ですが英語->日本語->英語の例です。元の文章(GitHubの公式より借用)が日本語を経て英語に戻しました。この文章ではあまり差はありませんが微妙に文章が違っていますね。
また、MITの調査によると、職への性別バイアスがある言語があるらしいです。この例はHeとSheが同じ単語で表される言語だと問題になるみたいですね。
Bias in AI: translating English to Turkish, a gender neutral language, then that same Turkish phrase back to English (credit @_DianeKim) pic.twitter.com/XfAUIxiaxg
— MIT CSAIL (@MIT_CSAIL) February 27, 2018
KaggleのA simple technique for extending datasetというディスカッションも参考になると思います。
逆翻訳の実装
実装にはssut/py-googletransを使いました。翻訳は以下のように簡単に行うことができます。
from googletrans import Translator
translator = Translator()
text = 'メロスは激怒した。'
translator.translate(text, dest='en').text
# >> Meros was furious
なおその他の対応言語については公式ドキュメントに書いてあります。
以下が実際にBBCのデータセットを使ったサンプルコードです。
なおbbc-text.csvは以下のようなデータになっています。
| category | text |
|---|---|
| tech | tv future in the hands of viewers with home theatre systems plasma high-definition tvs and digital… |
| business | worldcom boss left books alone former worldcom boss bernie ebbers who is accused of overseeing an… |
| sport | tigers wary of farrell gamble leicester say they will not be rushed into making a bid for andy far… |
import pandas as pd
import time
from googletrans import Translator
df = pd.read_csv('bbc-text.csv')
data = df
print('create_back_translated_df()')
translator = Translator()
back_translator = Translator()
ja_back_translated_list = []
zh_back_translated_list = []
for index, row in df.iterrows():
ja_translate = translator.translate(row.text, dest='ja').text
time.sleep(1)
ja_back_translate = translator.translate(ja_translate, dest='en').text
time.sleep(1)
ja_back_translated_list.append(ja_back_translate)
zh_translate = translator.translate(row.text, dest='zh-cn').text
time.sleep(1)
zh_back_translate = translator.translate(zh_translate, dest='en').text
time.sleep(1)
zh_back_translated_list.append(zh_back_translate)
print('Translated: row[' + str(index) + ']')
data['ja-en-text'] = ja_back_translated_list
data['zh-en-text'] = zh_back_translated_list
print(data)
翻訳ごとの間にsleep(1)を入れています。これがないとたまに翻訳が行われずにそのままの文章が返ってくることがあるためです。
上のスクリプトを実行すると横に翻訳データが増えていきます。
| category | text | ja-en-text | zh-en-text |
|---|---|---|---|
| tech | tv future in the hands of viewers with home theatre systems plasma high-definition tvs and digital… | tv future in the hands of viewers with home theatre systems plasma high-definition tvs and digital… | tv future in the hands of viewers with home theatre systems plasma high-definition tvs and digital… |
| business | worldcom boss left books alone former worldcom boss bernie ebbers who is accused of overseeing an… | worldcom boss left books alone former worldcom boss bernie ebbers who is accused of overseeing an… | worldcom boss left books alone former worldcom boss bernie ebbers who is accused of overseeing an… |
| sport | tigers wary of farrell gamble leicester say they will not be rushed into making a bid for andy far… | tigers wary of farrell gamble leicester say they will not be rushed into making a bid for andy far… | tigers wary of farrell gamble leicester say they will not be rushed into making a bid for andy far… |
まとめ
ここではテキスト水増しの逆翻訳のみについて書きました。他の水増し手法についてはnplaugというライブラリを使うと楽に実装できそうです。