はじめに
pandasで集計をする際に必須なgroupby。
分析をするときには気にならないことが多いですが、システムとして運用する時は実行速度が求められてきます。
今回はgroupbyをする際に、byに指定するカラムの型をint, float, str(object), categoryにして実行速度を測定、比較をしていきます。
ライブラリ
import random
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
データ準備
ダミーデータの準備です。
ベースとなるidは30個とします。
sample_id_list = [i for i in range(30)]
print(sample_id_list)
"""出力
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29]
"""
ダミーデータを作成する関数です。
def create_sample_dataframe(sample_id_list, row_num):
data = []
for _ in range(row_num):
sample_id = random.choice(sample_id_list)
sample_value = np.random.rand(1)[0]
data.append([sample_id, sample_value])
df = pd.DataFrame(
data=data,
columns=["id_int", "value"],
)
df["id_float"] = df["id_int"].astype(float)
df["id_str"] = df["id_int"].astype(str)
df["id_categorical"] = df["id_int"].astype("category")
df = df[["id_int", "id_float", "id_str", "id_categorical", "value"]]
return df
作成した関数のチェック
row_num = 100
df = create_sample_dataframe(sample_id_list, row_num)
print(df.head())
"""出力
id_int id_float id_str id_categorical value
0 24 24.0 24 24 0.136070
1 10 10.0 10 10 0.852180
2 3 3.0 3 3 0.440633
3 19 19.0 19 19 0.350676
4 14 14.0 14 14 0.246365
"""
print(df.info())
"""出力
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 100 entries, 0 to 99
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id_int 100 non-null int64
1 id_float 100 non-null float64
2 id_str 100 non-null object
3 id_categorical 100 non-null category
4 value 100 non-null float64
dtypes: category(1), float64(2), int64(1), object(1)
memory usage: 4.8+ KB
"""
想定通りの型になっています。
測定コード
今回は以下の行数を対象に測定していきます。計測はnotebookの%timeitで行います。関数としては今回はsumを対象にします。
row_num_list = [
100,
1000,
10000,
100000,
1000000,
10000000,
100000000,
]
for row_num in row_num_list:
print("***", row_num, "***")
df = create_sample_dataframe(sample_id_list, row_num)
%timeit df[["id_int", "value"]].groupby("id_int").sum()
%timeit df[["id_float", "value"]].groupby("id_float").sum()
%timeit df[["id_str", "value"]].groupby("id_str").sum()
%timeit df[["id_categorical", "value"]].groupby("id_categorical").sum()
実験結果
それでは結果を見ていきましょう。実行時間の単位[ms]です。
# result_dfは手で作成、ほんとはtimeitをうまく使えばいいのですが、ご愛嬌。
print(result_sum_df)
"""出力
id_int id_float id_str id_categorical
100 1.51 1.52 1.65 1.56
1000 1.65 2.12 3.04 2.18
10000 2.23 2.37 3.01 1.88
100000 4.09 5.20 10.70 2.65
1000000 25.80 33.00 90.10 13.40
10000000 223.00 294.00 825.00 108.00
100000000 3570.00 3570.00 26200.00 1950.00
"""
result_sum_df.plot()
ax = plt.gca()
ax.set_xscale('log')
plt.xlabel('row number')
plt.ylabel('time[ms]')
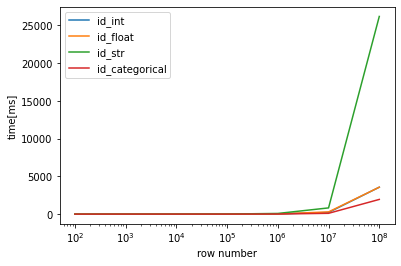
categoryが全体的に早い印象ですね。その次がintで、若干遅くなりますがfloatもそれと同等。str(object)はやけに遅いの避けた方がよさそうです。
最後に
groupbyするとき型がstrだったことが結構多いので気をつけます。