はじめに
Fast NumPy array functions written in C.
ドキュメントに記述されている通り、bottleneckはNumpyの一部の関数をC言語で書いたものであり、Cで書かれてるが故に処理時間が早いというのが主張です。
ではどのくらい早いのか。それをnumpyの実行時間と比較していきます。
なお今回はFunction referenceに記載されているreduceの部分の比較をしていきます。(※ss,anynan,allnanはnumpyに実装されていないため対象外)
インストール
$ pip install bottleneck
(参考)ベンチマーク
bottleneckではbn.bench()とすることで提供されている関数の性能を出力してくれます。
import bottleneck as bn
bn.bench()
"""出力結果
Bottleneck performance benchmark
Bottleneck 1.3.4; Numpy 1.19.2
Speed is NumPy time divided by Bottleneck time
NaN means approx one-fifth NaNs; float64 used
no NaN no NaN NaN no NaN NaN
(100,) (1000,1000)(1000,1000)(1000,1000)(1000,1000)
axis=0 axis=0 axis=0 axis=1 axis=1
nansum 24.3 0.6 2.2 0.7 2.4
nanmean 91.6 1.5 2.1 2.1 2.4
nanstd 112.7 1.2 2.3 1.4 2.6
nanvar 110.0 1.2 2.2 1.3 2.6
nanmin 22.4 0.5 0.5 0.9 1.1
nanmax 21.1 0.4 0.5 1.0 1.1
median 87.0 1.5 5.8 1.1 6.2
nanmedian 116.0 4.6 5.1 4.6 4.9
ss 13.8 0.9 1.0 0.9 1.0
nanargmin 41.4 2.9 4.7 1.7 4.3
nanargmax 42.0 2.5 4.7 2.1 4.5
anynan 11.3 0.4 93.3 0.6 76.6
allnan 18.0 199.0 168.6 160.2 138.6
rankdata 41.4 1.7 1.8 2.0 2.1
nanrankdata 76.4 1.8 1.9 2.5 2.1
partition 3.8 0.9 1.5 0.9 1.2
argpartition 2.9 1.2 1.5 1.1 1.5
replace 13.7 2.2 2.3 2.2 2.3
push 1432.7 7.2 7.8 11.0 10.7
move_sum 2607.6 61.4 124.7 147.2 195.1
move_mean 6155.1 110.5 135.1 270.1 250.7
move_std 8696.5 111.1 237.5 222.1 345.0
move_var 8482.2 122.8 224.2 221.3 339.8
move_min 896.9 16.2 16.2 40.1 42.3
move_max 913.7 14.4 14.9 42.8 42.0
move_argmin 2022.4 44.3 89.7 68.0 80.7
move_argmax 1874.9 46.4 80.0 52.3 119.7
move_median 1757.8 147.1 161.8 155.9 149.8
move_rank 1150.9 1.4 1.4 2.1 1.9
"""
検証
データ準備
今回の検証ではベンチマークのコンディションに則って測定していきます。 コンディションは以下の通り。
- no NaN / (100,) / axis=0
- no NaN / (1000, 1000) / axis=0
- NaN / (1000, 1000) / axis=0
- no NaN / (1000, 1000) / axis=1
- NaN / (1000, 1000) / axis=1
なので必要なデータは以下の3つ。3ポチ目に関してはNaNを1/4ほど忍び込ませておきます。
- no NaN / (100,)
- no NaN / (1000, 1000)
- NaN / (1000, 1000)
それではデータを作成します。
import numpy as np
np.random.seed(seed=42)
# no NaN / (100,)
data_1 = np.random.rand(100)
# no NaN / (1000, 1000)
data_2 = np.random.rand(1000, 1000)
# NaN / (1000, 1000)
data_3 = data_2.copy()
data_3.ravel()[np.random.choice(data_2.size, int(data_2.size/4), replace=False)] = np.nan
準備完了!
測定コード
今回の測定ではnotebookの%timeitで計測しています。
nansumの場合だと以下のようにコードに書き、それぞれのコンディションについて測定しています。
%timeit np.nansum(data_1, axis=0)
実験結果
早速ですが、実験結果です。
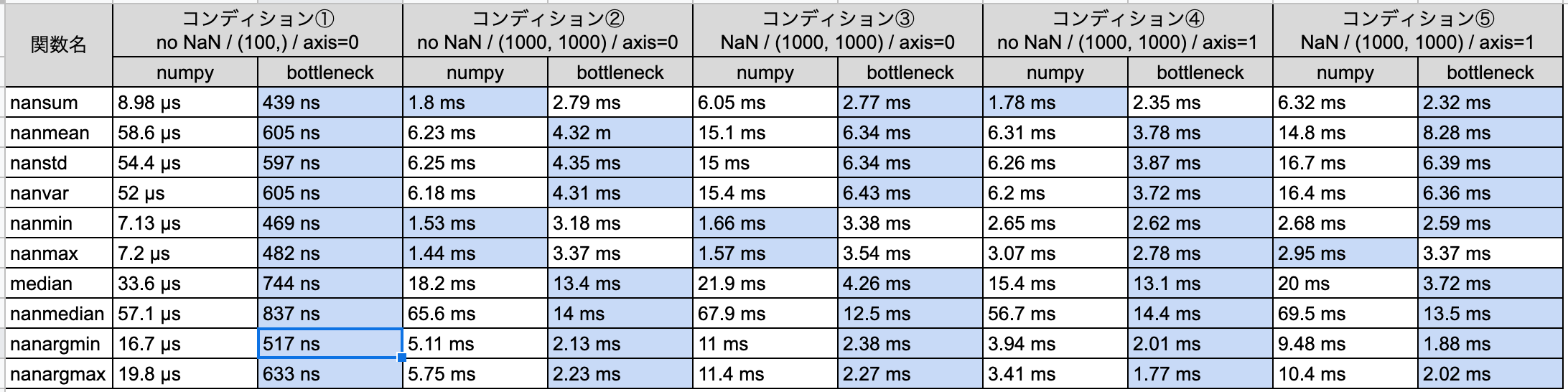
bottleneckの方が全体的に早くなっている一方で、一部のコンディションにおいてはnumpyの方が早くなっていますね。
考察としては以下の点が挙げられます
- 1次元においてはbottleneckが爆速!コンディション①の結果をみると明確ですが、実行時間の単位が違うので爆速なことがわかります。
nansumにおいてはNaNを含まない時はnumpy, NaNがあるときはbottleneckの方が早い。ただbottleneckにした方がNaNがあった場合の恩恵が倍以上。nanmin,nanmaxにおいてはnumpyの方が無難。特にaxis=0の場合、numpyだとbottleneckより倍早い。
最後に
測定するの割と疲れた